
LangChain #17: Vector Retrievers
Advanced Retrieval Techniques


Retrieval in LangChain serves as a vital component in connecting external data to language models (LLMs). By employing sophisticated retrieval methods, LangChain enhances the contextual relevance and accuracy of responses. This article delves into the functionality and examples of vector store retrievers and other advanced retrieval techniques.
Vector Store Retriever Basics
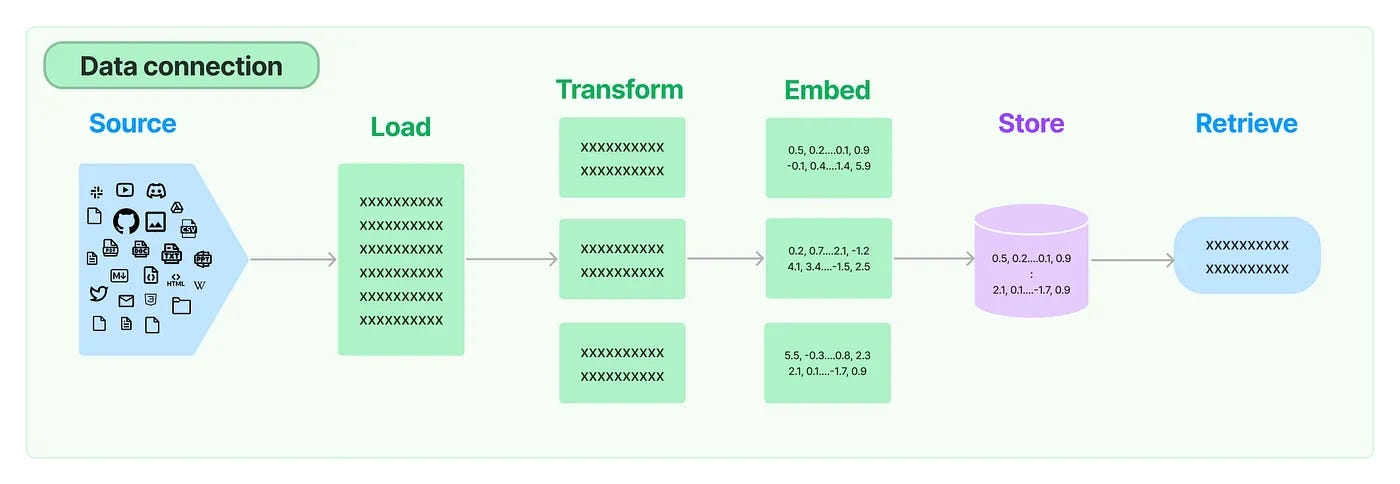
A vector store retriever uses vector embeddings to retrieve documents, providing a streamlined interface to the Vector Store class. It supports similarity search and Maximal Marginal Relevance (MMR) to balance relevance and diversity in results. As a critical part of the data pipeline, retrieval bridges the gap between external data sources and LLMs, enabling them to utilize information beyond their training.
Example Workflow
Text Loading and Splitting
Use the
TextLoaderclass to load text content into a document list.Split the document into chunks with
CharacterTextSplitter:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=30, separator=" ")
texts = text_splitter.split_documents(documents)
print(len(texts)) # Example output: 21Embedding and Storage
Generate embeddings using
SentenceTransformerEmbeddingswith theall-MiniLM-L6-v2model.Store embeddings in a Chroma vector store:
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)Creating a Retriever
Convert the vector store into a retriever:
retriever = db.as_retriever(search_kwargs={"k": 2})The search_kwargs parameter specifies the top 2 most relevant results to return.
Retrieving Documents
Search for relevant documents:
docs = retriever.get_relevant_documents("What is the purpose of the book?")Advanced Retrieval Techniques
1. Maximal Marginal Relevance (MMR)
MMR optimizes retrieval by balancing relevance and diversity:
retriever = db.as_retriever(search_type="mmr")
docs = retriever.get_relevant_documents("What is the purpose of the book?")This method often retrieves more diverse results.
2. MultiQueryRetriever
To mitigate sensitivity to query phrasing, the MultiQueryRetriever generates query variations:
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0.1)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=db.as_retriever(), llm=llm)
docs = retriever_from_llm.get_relevant_documents(query="What is the purpose of the book?")3. Contextual Compression
To reduce irrelevant data, ContextualCompressionRetriever filters and condenses retrieved documents:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("What is the purpose of the book?")This approach ensures only the most pertinent content is processed.
4. Ensemble Retriever
Combine multiple retrievers for enhanced performance using the EnsembleRetriever:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25 = BM25Retriever.from_documents(texts)
ensemble_retriever = EnsembleRetriever(retrievers=[bm25, retriever], weights=[0.5, 0.5])
docs = ensemble_retriever.invoke("What is the purpose of the book?")This hybrid search leverages both keyword-based and semantic-based retrieval.
5. Long-Context Reorder
Reordering documents ensures the most relevant information is prioritized:
from langchain_community.document_transformers import LongContextReorder
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)6. MultiVector Retriever
Using multiple vectors per document improves precision:
Split documents into chunks or summarize to create embeddings tailored for diverse queries.
7. Parent Document Retriever
This retriever fetches smaller document parts along with their larger parent context to balance detail and overarching relevance.
8. Self-querying
Automatically generate and execute structured queries:
# Example usage with LLM-based chain for self-querying9. Time-weighted Vector Store Retriever
This retriever prioritizes recently accessed data with a time decay factor:
semantic_similarity + (1.0 - decay_rate) ^ hours_passed10. Third-Party Retrievers
LangChain integrates with platforms like arXiv:
from langchain_community.retrievers import ArxivRetriever
retriever = ArxivRetriever(load_max_docs=2)
docs = retriever.get_relevant_documents(query="1605.08386")Conclusion
LangChain's retrieval module demonstrates advanced techniques for connecting external data with LLMs. From basic vector store retrievers to sophisticated contextual compression and ensemble methods, these tools enhance the relevance and accuracy of language model outputs, creating more effective and contextually aware conversational AI systems.